연구과제
연구 과제명
인간의 한국 한시 향유와 기계의 한국 한시 분석의 만남 : 시맨틱 큐레이션과 워드임베딩 기술을 활용한 한국 한시 데이터 프로세싱
(Exploring the Intersection of Human Enjoyment and Machine Analysis : Utilizing Semantic Curation and Word Embedding Technology to Process Sino-Korean Poetry Data)
※ "2024년 한국연구재단 글로벌인문사회융합연구지원사업"
연구 개요
본 연구는 조선 전∙중기에 편찬된 약 20가지 시문집에 수록된 약 17,500여 수, 83만여 자 분량의 한시를 수집∙정리∙검토하고, 해당 시기의 한시 작가를 다룬 약 430여 건(학위논문 약 130여 건, 학술논문 약 300여 건) 이상의 논저를 정리∙체계화함으로써 조선 전∙중기 한시 지식그래프를 구현할 수 있는 시맨틱 데이터를 편찬하는 것을 목표로 한다. 나아가 해당 데이터를 대상으로 공기어분석, 토픽모델링, 워드임베딩을 매개한 딥러닝 모델 등 자연어처리 기반의 다양한 데이터 분석 연구를 수행함으로써, 해당 데이터와 분석 알고리즘을 모두 담아낸 한시 데이터 아카이브를 웹상에서 제공함과 동시에, 그러한 연구 전체의 내용과 학술적 의미를 종합적으로 정리한 연구 논저를 간행하고자 한다.
이 연구는 다음과 같은 기대효과를 가지고 있다. ①한국 한시 데이터셋 개방을 통해 디지털 한문학 연구의 기초 자원을 확보하면서, 이를 통해 ②한문학 연구에서 자연어처리(NLP) 기술의 활용 가능성을 탐색하고 워드임베딩 기술의 접목 방안을 검토한다. 이러한 연구 과정에서 ③디지털 인문학 전문 연구 인력을 양성하고, 궁극적으로 ④종합적인 성격을 지닌 한국 한시 데이터 아카이브를 제공하여 한국 한시의 문화적 가치를 소개할 수 있는 장을 제공하고자 한다.
연구 방법
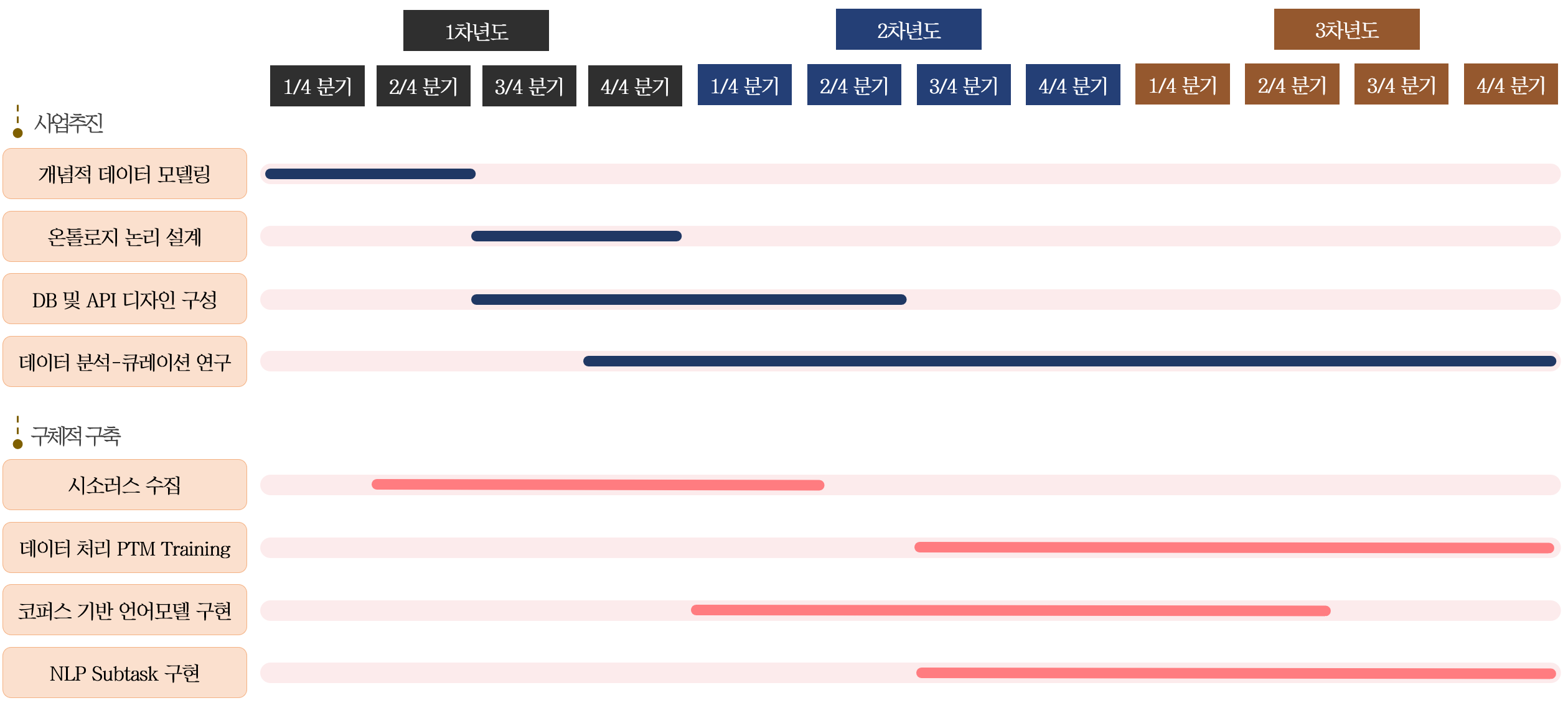
본 연구는 온톨로지 기반의 데이터 디자인(data modeling), 디자인한 내용을 토대로 한 데이터셋 편찬(data construction), 그리고 편찬된 데이터셋 대상 기계학습을 활용한 분석(data analysis) 연구를 각각 모듈화하여 3년간 연구를 진행할 것이다. 각 연구 수행 일정의 분기별로 주요 마일스톤을 설정하고, 선행 작업의 진행도에 따라 연구 방침을 아래 <그림>의 예시처럼 유연하게 적용하여 연구 효율을 극대화하고자 한다.
과업은 크게 데이터 모델링 및 데이터셋 편찬과 데이터 분석 및 큐레이션 작업으로 나누어볼 수 있다. 한국 한시 자료를 대상으로 데이터를 디자인하고 실제 데이터를 편찬하는 과정에서는, 한시를 전공한 인문학 연구자가 중심이 되어 이공계열 연구자가 지원하고, 편찬된 한국 한시 데이터셋을 대상으로 데이터(텍스트)를 분석하고 큐레이션하는 과정에서는 데이터베이스와 자연어처리 기술 및 기계학습 알고리즘을 다루는 이공계 연구자를 중심으로 한시를 전공한 인문학 연구자가 지원하는 형식으로 과업을 진행하고자 한다.
현재는 연구 대상을 전수 조사하고 유관 연구 성과를 검토하며 이를 바탕으로 온톨로지를 디자인하고 한국한시에 대한 기초 데이터모델링을 위한 데이터샘플링 작업을 진행 중에 있다.
연구 내용
본 연구는 인간이 그간 전통적으로 향유하였던 한시에 관한 심층적인 이해의 과정을 분석적으로 살펴보고 이를 AI에게 학습시켜 인간과 기계가 한시라는 맥락적인 문학을 어떻게 해석하는지에 대해 상호 비교해 보고자 하는 동기에서 기인하였다. 본 연구에서는 기계 가독이 가능하면서도 구체적인 정보를 포괄하고 있는 한국 한시 데이터셋을 구축하는 데 중점을 두고 있다. 예컨대 한시에서 사용되는 낱글자와 시어(詞語)를 몇 가지 분류 기준으로 구분하여 그 사용 양태를 파악하고, 구 단위로 연계하여 대구를 형성하는 특징을 데이터 구조에 반영한다. 이러한 데이터의 축적과 그 활용을 통해 인간이 향유해 온 한시와 기계가 이해하는 한시의 현황을 확인하고, 그 맥락이 어떻게 다른지 그 특질을 변별적으로 비교∙고찰하여 볼 것이다. 분기별 진행 계획은 아래와 같다.
| 연차 | 연구 내용 | 연구시점 | 세미나 주제(횟수) |
|---|---|---|---|
| 1년차 | 대상 자료 분석 및 온톨로지 디자인과 개념적 데이터 모델링 | 전반기 6개월 | Ontology 디자인(3회) |
| 하반기 6개월 | |||
| 2년차 | 논리적∙물리적 데이터 모델링 및 데이터셋 편찬 / 분석 방안 연구 | 전반기 6개월 | No-SQL(Graph, Document) DB 운용(3회) |
| 하반기 6개월 | |||
| 3년차 | 편찬 데이터셋 대상 데이터 분석 및 큐레이션 연구 | 전반기 6개월 | Text Analysis / Network Theory(3회) |
| 하반기 6개월 |
연구인력 현황
| 직급 | 성명 | 소속 |
|---|---|---|
| 연구책임자 | 임준철 | 고려대학교 한문학과 |
| 공동연구원 | 정성훈 | 목포대학교 국어국문학과 |
| 유인태 | 전남대학교 중어중문학과 | |
| 정태선 | 아주대학교 소프트웨어학과 | |
| 이도길 | 고려대학교 민족문화연구원 | |
| 연구원 | 지영원 | 고려대학교 한자한문연구소 |
| 송채은 | 고려대학교 한자한문연구소 | |
| 이예리 | 고려대학교 한자한문연구소 | |
| 이길환 | 고려대학교 한자한문연구소 |
연구과제
과제명
한문과 우리말 쌍의 <연행록> 객체 및 객체간 관계 태깅
사업 내용
ㆍ사업명: 2021년도 KAIST ‘김재철 AI 발전기금’ AI Dataset Challenge 사업
ㆍ주관기관: 한국과학기술원 (KAIST)
ㆍ협력기관: 고려대학교 한문학과, 한국고전번역원
연구 기간
2021.11.1~2022.6.30
연구 참여진
ㆍ연구책임자: 주재걸(KAIST 김재철AI대학원 교수)
ㆍ연구원: 양소영(KAIST 인공지능연구원 연구원)
ㆍ협력연구원: 임준철(고려대학교 한문학과 교수), 양원석(고려대학교 한문학과 부교수), 송호빈(고려대학교 한문학과 조교수),
선보민(한국고전번역원 고전정보팀 팀장)
연구 개요
한국 고전 종합 DB는 9억 자에 가까운 양의 한국 고전 문헌 자료를 오픈 소스로 공개하고 있으나, 한문과 우리말 쌍의 텍스트만 존재하여 기존 연구의 경우 기계 번역 및 한자 복원 태스크만 진행하였다. 이는 인공지능 연구를 한국 한문 데이터셋에 활용하는데 접근성을 떨어뜨리므로, 번역 외의 태스크를 진행할 수 있는 별도의 데이터셋 구축이 필요하다. 따라서, 본 연구진은 한문과 한글 쌍으로 이루어진 <연행록> 말뭉치에 대한 병렬 태깅 데이터셋인 Historical Document-Level Relation Extraction Dataset (HistDRED)를 구축하였으며, 이는 추후 오픈소스 데이터셋으로 공개될 예정이다.
연구 결과
태깅 작업에 앞서 고려대 한문학과 교수진과 긴밀한 협업을 통해 <연행록>에 적합한 객체 타입 10종, 관계 타입 20종을 정의하였다. 이때 객체란 유의미한 사람, 기관과 같은 유의미한 말뭉치이며, 관계는 객체 사이의 유의미한 정보이다. 예를 들어 ‘잡스는 애플의 창업자이다.’라는 문장에서 ‘잡스’와 ‘애플’은 각각 사람, 기관 객체이며 두 객체 사이에는 ‘잡스 → 애플’ 사이에는 ‘창업자(founder)’라는 관계가 존재함을 알 수 있다.
두 달간의 태깅 작업 이후 원본 데이터를 인공지능 모델 학습에 적합한 형태로 재구축하였다. 결과적으로 5,862개의 데이터 인스턴스가 생성되었으며, 실제 한 인스턴스 당 한국어 문장 개수의 분산이 기존 1,503에서 4.15로 줄어들어 모델 학습에 용이한 형태를 갖추게 되었다. 한 데이터 인스턴스가 포함한 정보는 크게 세 종류를 포함하는데, (1) 한문 원본, 국문본 두 텍스트와 (2) 각 텍스트에서의 객체와 객체 간 관계 정보, 그리고 (3) 텍스트와 관련된 책 제목, 작성 연도와 같은 메타 정보를 포함한다. <그림 1>의 경우 데이터셋 예시이다.
나아가 한문과 우리말의 병렬 말뭉치로 구성된 HistRED의 구조를 고려한 맞춤형 bilingual relation extraction model을 제안하였다. 맞춤형 모델의 경우 기존 단일 언어 모델보다 안정적으로 높은 성능을 보여준다.

<그림 1> 데이터셋 예시